tacc - The Alternative Compiler Compiler
tacc: Version: 4.56.2.81 32 bit, Compiled: Jun 25 2021 at 01:46:21 (c) Trevor Boyd 19 Mar 2014
tacc: Version: 4.56.2.81 64 bit, Compiled: Jun 25 2021 at 02:19:21 (c) Trevor Boyd 19 Mar 2014
Download tacc - Windows 32 bit and 64 bit
Introduction
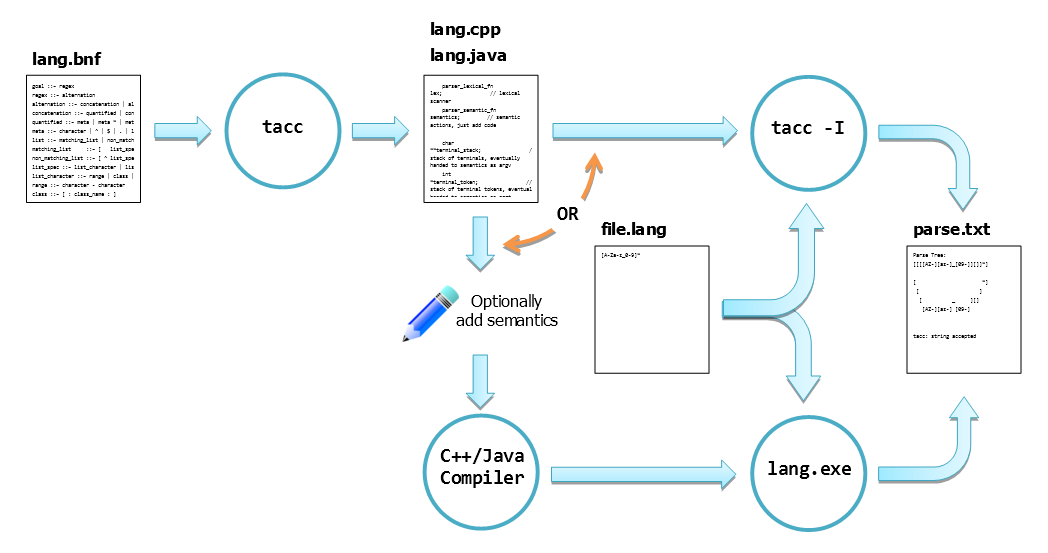
tacc
tacc is a compiler compiler.
tacc compiles a simple BNF like grammar and outputs (LA)LR(1) parser source code in C++ or Java with a built in lexical scanner.
You can compile the output .cpp with a C++ or Java compiler or you can use tacc -I to "interpret" the .cpp file.
The resultant parse from either method is identical. The C++ output.cpp file is built from the actual source code of the tacc when tacc is compiled.
The ability to test your grammar and syntax check any file in your target language without having to compile the .cpp or build your own lexical scanner can greatly speed up the development of your language parser.
You can add semantic actions directly to the bnf or you can add them later manually to the output .cpp file.
 |
tacc Features
Similar in function to yacc and lex put together.
Elegant simplicity
- Easy to use: tacc lang.bnf -o lang.cpp
- Simple BNF like syntax will accept many grammars as is
- tacc tries hard to work out what you want instead of giving you errors
Lots of automatic and default components, tacc just works it out for you.
- no need to define what is a token
- no need to specify which tokens are terminal or not
- no precedence rules, in fact there is no extra guff at all
- templates are built in to the exe, no need to look for that .tab file
- or extract the built in templates and modify them yourself
Powerful default lexer
- regular expression matching
- context aware lexer makes supporting subsystem grammars easy
- regexes are simply prioritised in the same order as in the grammar
- custom regex engine matches all tokens in parallel
- token matching speed is independent of the number of regexes
- automatic or manual whitespace and end of line control
Interpreter mode
- speeds up turnaround on grammar development
- you don't even need a C++/Java compiler to parse your target language input
Rich trace and debug
- Many options so you can see how LR(1) grammars are created (instructive).
- Rich set of trace options to see what your grammar is doing.
- Trace options in tacc also carry over to your target language parser
tacc Drawbacks
Parts of tacc were written before 1993, so it is a bit old school in some areas:
- not the fastest compiler compiler on the block (but the generated code is fast)
- no precedence rules means you have to do it with the grammar
Simple Example
Create a grammar.bnf
Let's write a simple parser to recognise a stream of typical variable names (identifiers).
Identifiers start with a letter or underscore and are optionally followed by letters, underscore and numbers.
The grammar for the identifier stream is:
> cat identifiers.bnf
GOAL ::= ids
ids ::= id | ids id
id ::= /[A-Za-z_][A-Za-z_0-9]*/
By default, the parser generated with tacc automatically handles whitespace, so we don't need to worry about it here.
The first token encountered in the BNF file is the goal token. The entire parse will eventually end up as the goal token.
Tokens can be plain text or /regular expressions/. Regular expressions match the leftmost longest string in the input. If more than one token matches the input, and they are the same length, then the one that is specified first in the bnf file has priority. This means you can put keywords before generic regexes that catch identifiers and have them correctly tokenised as keywords.
Compile the grammar.bnf to grammar.cpp with tacc
Compile the bnf with tacc:
> tacc identifiers.bnf -o identifiers.cpp
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc: using internal template: default (vogue)
tacc: output file is: identifiers.cpp
Execute the grammar.cpp with the tacc -I interpreter
Test it out with tacc -I:
> tacc -I identifiers.cpp "this and that"
tacc: string accepted
> tacc -I identifiers.cpp "this then 9fail"
tacc: Error: Unrecognised input "9fail"
1: this then 9fail
^^^^^
Or compile the grammar.cpp with C++
Or you can compile identifiers.cpp with a C++ compiler:
> cl /EHsc /nologo /O2 identifiers.cpp /Feidentifiers.exe
identifiers.cpp
Test it out with identifiers.exe:
> identifiers.exe "this and that"
identifiers: string accepted
> identifiers.exe "this then 9fail"
identifiers: Error: Unrecognised input "9fail"
1: this then 9fail
^^^^^
Apart from the program name, the output is the same.
Command line options
tacc -I and your exe also have command line options that can show you what is going on during the parse of your text. You can use -? To see them all
> identifiers.exe -?
usage: identifiers { -f input_file | input_string... }
[-xrtasnlpvewb]
[-GWTV-?]
-options:
-f infile
-x print transitions
-r print reductions
-t print tokens as they are read (-ttt... -K = max t's)
-a print terminal args with reductions
-s print top of parse tree stack with reductions (needs -p)
-n only print reductions that have terminal args
-l print lookahead with reductions
-p print parse tree, -pp print fancier parse tree
-v verbose, equivalent to -alrpptx
-e suppress expecting... output
-k don't use context aware lexing
-w don't ignore end of lines (\n, \f) (\r is always ignored)
-ww don't ignore any whitespace (\n \f \v \t ' ') (\r is always ignored)
-b print the BNF source for this program
-B print the input string or filename
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-V Version
-- Stop -option parsing
-? This help message
These options are all explained in detail later on, but for now -rat is fun:
D:\Trev\Projects\tacc\Doc>identifiers.exe -rat "this and that"
lex: next token is {9 /id/ = "this"}
lex: next token is {9 /id/ = "and"}
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "this"
2: ids ::= id
lex: next token is {9 /id/ = "that"}
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "and"
3: ids ::= ids id
lex: next token is {2 EOS = ""}
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "that"
3: ids ::= ids id
1: GOAL ::= ids
Entering Semantics
It is nice to be able to recognise input, but it is better to be able to do something with it. The action you perform after parsing is semantics. You can add semantic actions directly to the .bnf grammar or you can add it to the default_semantics function in the output.cpp or even create your own. Generally the more complex the grammar and the more changes you make to the semantic code, the more likely you are to use cpp semantics. bnf semantics are for quick and simple grammars.
It might be a little easier to start with entering code into the output.cpp file.
cpp semantics
tacc generates a default semantic function for you to edit. The one for the identifiers.bnf grammar above looks like this:
int
default_semantics(int red, int argc, string argv[], token_info *argt[], string
&error)
{
// ---- Description
//
// default_semantics is a callback function
from the parser that gives you a reduction that is
// happening now and the strings that are
the terminals in that production.
You will normally
// perform some processing based on the
reduction number (red) and the arguments in argv.
//
// ---- Parameters
//
// red - the reduction (production)
number.
//
// argc - the count of terminal token
strings in argv
//
// argv[] - Reduction terminal token
strings (the values of the tokens that are "variables")
//
// argv[0] is the
leftmost terminal token string
// argv[1] is the
next leftmost terminal token string
// ...
// argv[argc - 1]
is the rightmost terminal token string
// argv[argc] is the
lookahead token string
//
// argt[] - Reduction terminal token
info
//
//
argt[0]->token - the token id number
//
// Usually you
would only use .token, but see class token_info for others.
//
// error - an optional error message that
will be printed if you return non 0 from this function.
//
So if you found a semantic error on token 0 and wanted to stop parsing,
you would:
//
//
error = argt[0]->token_error("ERROR: I'm sorry, Dave, I'm afraid I
can't do that.");
//
return 1;
//
// return value: 0 = all OK and keep
parsing. Non 0 = error and stop
parsing.
//
// ---- Example
//
// 17. EXPR ::= /[0-9]+/
OPERATOR /[A-Za-z_][A-Za-z_0-9]*/
//
37
goo
;
//
// red = 17
- the number of the reduction, ie the 17th production in your
.bnf
// argc = 2
- the number of terminal tokens, here they are "37" and "goo"
// argv[0] = "37" - the value of the
first terminal token
// argv[1] = "goo" - the value of the second
terminal token
// argv[2] = ";" - the lookahead
token
// argt[0]->token = 7 - the
token for number, ie the 7th token defined in your .bnf
// argt[1]->token = 9 - the
token for identifier, ie the 9th token defined in your .bnf
//
// EXPR is what you are
calculating here, most likely you will push this result on your
// own weird stack.
//
// OPERATOR is a non terminal,
most likely you will have OPERATOR ::= + | - | ...
// somewhere in your
.bnf.
//
switch (red) {
case 1 : // GOAL ::= ids
break;
case 2 : // ids ::= id
case 3 : // ids ::= ids id
break;
case 4 : // id ::= /[A-Za-z_][A-Za-z_0-9]*/
break;
case 0:
default :
// printf("Unhanded or unknown reduction =
%d\n", red);
//
exit(EXIT_FAILURE);
break;
}
return 0;
}
Adding cpp semantics
So if we wanted to print out a message when we read in an id, we could put it in the code like this:
case 4 : // id ::= /[A-Za-z_][A-Za-z_0-9]*/
printf("id = %s\n",
argv[0].c_str());
break;
Compiling it and running it gives:
> identifiers.exe this and that
id = this
id = and
id = that
identifiers: string accepted
Note that we could not have put the printf under case 2 or 3 because the right hand side (RHS) of the ::= are all non terminals (ie they appear as a left hand side (LHS) somewhere else in the grammar). If you want to retain the id for later processing by higher order rules, the usual way is to push the values onto a stack. We will see how to do that a bit further on.
bnf semantics
You can enter code directly into the bnf by putting it inside braces after the rule it matched like this (and it has to be pretty much exactly like this):
GOAL ::= ids
ids ::= id | ids id
id ::= /[A-Za-z_][A-Za-z_0-9]*/
{
printf("id = %s\n", argv[0].c_str());
}
tacc, compile and execute gives us the same result as putting it directly into the .cpp:
> identifiers.exe this and that
id = this
id = and
id = that
identifiers: string accepted
Note that tacc -I cannot interpret the semantic actions (aww...). tacc can only interpret the tables it generated in the cpp file. Disappointing, I know, but I wasn't writing an entire C++ interpreter. Besides, you can use your own template file and it need not be C++.
Named Sections
If you want to put some code in the bnf file that is global, you can put it in a named section.
Let's say we wanted to read in the identifiers and output them all at once with commas between them. We need to change the grammar slightly so that the ids ::= id | ids id is split into separate lines and add some { semantic blocks }
So input:
this and that
Outputs:
List: this, and, that
The default tacc template has a tacc_include and a tacc_global that we can use like this:
tacc_include
{
#include <iostream>
using std::cout;
#include <string>
#include <stack>
}
tacc_global
{
typedef std::stack<std::string> string_stack;
string_stack aux;
}
GOAL ::= ids
{
string list = aux.top(); aux.pop();
cout << "List: " << list << "\n";
}
ids ::= id
{
string id = aux.top();
cout << "leaving id = " << id << " on the stack\n";
}
ids ::= ids id
{
string id = aux.top(); aux.pop();
cout << "pop id = " << id << "\n";
string list = aux.top(); aux.pop();
cout << "pop list = " << list << "\n";
list = list + ", " + id;
cout << "pushing list = " << list << "\n";
aux.push(list);
}
id ::= /[A-Za-z_][A-Za-z_0-9]*/
{
cout << "pushing id = " << argv[0] << "\n";
aux.push(argv[0]);
}
tacc, compile and execute gives us:
> identifiers.exe this and that
pushing id = this
leaving id = this on the stack
pushing id = and
pop id = and
pop list = this
pushing list = this, and
pushing id = that
pop id = that
pop list = this, and
pushing list = this, and, that
List: this, and, that
identifiers: string accepted
It may seem like a kinda crazy way to get that string to the next higher level rule by popping and pushing, but it is very common to do it like that.
You might also pop values off the stack, perform some processing and push the result back on as we do to put the comma in the list.
It is also normal to have a stack that is a union of many types.
A named section may have any name. The name given is matched to a comment in the template file that tacc uses to generate the cpp file.
You can list the templates built in to tacc and export them for perusal like this:
> tacc -d
Name Ext Default Description
-------- ---- ------- ----------------------------------------------------------------
classic cpp No Older C++ template with no real redeeming features.
sienna cpp No C++ template generated around tacc 4.03. Still good.
vogue cpp Yes C++ template generated from the tacc source code.
jive java No Simple Java template for tiny grammars.
juke java Yes Java template with parser tables in *.joos.dat files.
cup cup Yes Convert to CUP parser format. Not perfect.
default * * Matches a default template above by output file extension.
> tacc -M default -o template.cpp
Named sections look like this:
//
>>>> tacc directive
[arguments]
Most of them are only really useful if you are building your own template file.
Directive is one of these.
tacc_include
tacc_global
cpp_bnf_name
cpp_bnf_created
cpp_gen_author
cpp_tacc_info
cpp_command_line
cpp_bnf_source
cpp_tokens
cpp_transition_tokens
cpp_transition_actions
cpp_transition_state_index
cpp_reductions
cpp_string_tokens
cpp_regex_tokens
cpp_input_tokens
cpp_productions
cpp_case_semantics
cpp_regex_lex
cpp_context_lex_state
java_bnf_name
java_bnf_created
java_gen_author
java_tacc_info
java_command_line
java_bnf_source
java_tokens
java_transition_tokens
java_transition_actions
java_transition_state_index
java_reductions
java_string_tokens
java_regex_tokens
java_input_tokens
java_productions
java_case_semantics
java_regex_lex
java_context_lex_state
java_main_class
joos_app_info $dir/$name.app_info.joos.dat
joos_standard_tokens $dir/$name.standard_tokens.joos.dat
joos_transition_tokens $dir/$name.transition_tokens.joos.dat
joos_transition_actions $dir/$name.transition_actions.joos.dat
joos_transition_state_index $dir/$name.transition_state_index.joos.dat
joos_reductions $dir/$name.reductions.joos.dat
joos_string_tokens $dir/$name.string_tokens.joos.dat
joos_regex_tokens $dir/$name.regex_tokens.joos.dat
joos_input_tokens $dir/$name.input_tokens.joos.dat
joos_productions $dir/$name.productions.joos.dat
joos_regex_lex_state_action $dir/$name.regex_lex_state_action.joos.dat
joos_regex_lex_state_match $dir/$name.regex_lex_state_match.joos.dat
joos_context_lex_state $dir/$name.context_lex_state.joos.dat
joos_file_extension
cup_preamble
cup_lex
cup_cf
The named sections that start cpp, java and joos are used by tacc and are replaced with parser tables. To see a full description of every one of these, just browse through the comments in the template files.
$name is name of the input.bnf file without the extension, ie input.
$filename is the name of the input.bnf file, ie input.bnf
$dir is the directory of this automaton, from the dir/input.bnf or "." if not present
tacc doesn't use tacc_include or tacc_global, they are just custom named sections used by the cpp templates.
Custom Named Sections
You can make your own template.cpp and include your own named sections. For example if we modify the exported template.cpp from above and add a groovy section:
// >>>> tacc groovy
And put a groovy named section in the bnf:
groovy
{
// yeah this is groovy
}
Then use tacc with the new template with -m:
> tacc -m template.cpp identifiers.bnf -o identifiers.cpp
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc: using template file: template.cpp
tacc: output file is: identifiers.cpp
The output file contains:
// yeah this is groovy
In place of the:
// >>>> tacc groovy
That was in the template file.
Java
tacc can also do the same thing for java.
> tacc identifiers.bnf -o identifiers.java
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc: using internal template: default (juke)
tacc: output file is: identifiers.java
> javac identifiers.java
> java identifiers this and that
identifiers: string accepted
> java identifiers this and 9fail
identifiers: Error: Unrecognised input "9fail"
1: this and 9fail
^^^^^
> tacc -I identifiers.java this and that
tacc: string accepted
> tacc -I identifiers.java this and 9fail
tacc: Error: Unrecognised input "9fail"
1: this and 9fail
^^^^^
Fly Little Bird
That is really all you need to know to get started.
tacc -k Context Aware Lexing
tacc -k
Because
tacc creates both the lexer and the parser, it knows everything about the parser
when it is building the lexer. This
means that it can create a lexer that is specific to every parser
state.
Benefits:
- much
more flexibility in bnf specification
- allows
"subgrammars", like putting SQL SELECT statements in your language without
affecting the syntax of either the SQL or your language.
Drawbacks:
- bigger
lexer table (2-5x bigger, but they are usually small, in the order of
Kbytes)
- slower
tacc (4% slower build time)
- can
only return the error "unrecognised input ..." and not "unexpected token
'...'" (but the full lexer is always available if you want it to call it to
get error specific tokens. I
don't know if this is really that useful.)
Why
would you want to do that then?
Well
in some cases it is the only way.
Parsers have long separated the lexer from the parser and because of that
they have 1 big generic lexer that can recognise all of the tokens. tacc was no different, even though it
was all part of the same program, the lexer and the parser really didn't
interact that much. But now they do
and this can make some bnfs possible where previously they were
impossible.
For
example, let's say you had a language that recognised simple assignments of the
form:
id =
number
Potentially
separated by ; The bnf would look
like this:
GOAL ::=
program
program ::= program ; statement |
statement
statement ::= expression |
NULL
expression ::= id \=
number
id ::=
/[A-Za-z_][A-Za-z_0-9]*/
number ::=
/[0-9]+/
And
now you want to add a help command as well. The help command would be of the
form:
help
any_thing_at_all
Where
any_thing_at_all
really could be anything, including letters, numbers and even a
;
Conventional
lexers would have trouble with this.
Let's see why. First put the
new help command in the grammar: context.bnf:
GOAL ::=
program
program ::= program ; statement |
statement
statement ::= expression |
help_expression | NULL
help_expression ::= help
subject
expression ::= id \=
number
id ::=
/[A-Za-z_][A-Za-z_0-9]*/
number ::= /[0-9]+/
subject ::=
/[^[:space:]]+/
Compile
it with tacc and try it out:
> tacc context.bnf -o
context.cpp
And
try it out:
> tacc -I context.cpp -rt
"goo = 37"
lex: next token is {17 /id/
= "goo"}
lex: next token is {15 = =
"="}
9: id ::=
/[A-Za-z_][A-Za-z_0-9]*/
lex: next token is {18
/number/ = "37"}
lex: next token is {2 EOS =
""}
10: number ::=
/[0-9]+/
8:
expression ::= id = number
4:
statement ::= expression
3: program
::= statement
1: GOAL
::= program
context: string
accepted
Good
so far, but what happens if you take some of that whitespace
out?
> tacc -I context.cpp -rt
"goo=37"
lex: next token is {19
/subject/ = "goo=37"}
context: Error: Unexpected
input token: /subject/
1: goo=37
^^^^^^
found: /subject/, regex:
/[^[:space:]]+/
expecting: EOS program ; statement expression
help_expression help id /id/
The
trouble is the /subject/ regex is so inclusive it consumes all of the
input. But why should it? The only time the /subject/ regex is
used is after the keyword help.
How
about asking for help on ;
> tacc -I context.cpp -rt
"help ;"
lex: next token is {12 help
= "help"}
lex: next token is {8 ; =
";"}
context: Error: Unexpected
input token: ;
1: help ;
^
found:
;
expecting: subject /subject/
No
good either. Even though the
ordinary regex lexer whould have had the ; matched with ; and /subject/ for the
same length of 1, the bare ; has higher priority than /subject/ because it
occurs before it in the grammar. So
there
is
no way to allow the ; to be a parameter to the help
keyword.
If
you could limit looking for /subject/ only to the context when the previous
token was 'help' then you would be able to have your cake and eat it
too.
This
is what the tacc -k context aware lexer does. It only enables those input tokens that
can occur in the context of a particular parser state. Let's try it out:
> tacc -k context.bnf -o
context.cpp
tacc: reading grammar file:
context.bnf
tacc: checking
productions
tacc: building
automation
tacc: building
lexer
tacc: building context aware
lexer
Lexical contexts:
6
Lexical states: 11 normal + 5 contextual = 16
total
States:
15
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts:
0
Warnings: 0
Errors:
0
Automaton is
LR(1)
tacc: using internal
template: default (vogue)
tacc: output file is:
context.cpp
Now
let's try it out:
> tacc -I context.cpp -rt
"goo=37"
lex: next token is {17 /id/
= "goo"}
lex: next token is {15 = =
"="}
9: id ::=
/[A-Za-z_][A-Za-z_0-9]*/
lex: next token is {18
/number/ = "37"}
lex: next token is {2 EOS =
""}
10: number ::=
/[0-9]+/
8:
expression ::= id = number
4:
statement ::= expression
3: program ::=
statement
1: GOAL
::= program
context: string
accepted
And
you can ask help of practically anything, including the ;
> tacc -I context.cpp -rt
"help ;"
lex: next token is {12 help
= "help"}
lex: next token is {19
/subject/ = ";"}
lex: next token is {2 EOS =
""}
11: subject ::=
/[^[:space:]]+/
7:
help_expression ::= help subject
5:
statement ::= help_expression
3: program
::= statement
1: GOAL
::= program
context: string
accepted
Note
that tacc
-k
builds a context aware lexer in addition to the normal lexer. In tacc
-I
interpreter
mode and in your compiled cpp or java parser, the lexer will automatically use
the context aware lexer if available.
But if you want to temporarily disable context aware lexing you can use
tacc
-I
-k.
>
tacc -I -k context.cpp -rt "help ;"
lex: next token is {12 help
= "help"}
lex: next token is {8 ; =
";"}
context: Error: Unexpected
input token: ;
1: help
;
^
found: ;
expecting: subject /subject/
Formal tacc BNF Syntax
BNF
tacc was written with lesser versions of tacc (multiple times), so I should just put the tacc BNF here, but it is a bit scary looking, so I will included it later after we see some simple forms:
Comments
Comments are started with // and continue to the end of the line:
// this is a comment
Productions
Productions or rules are simply a single identifier ::= (becomes) some other identifiers. LHS (left hand side) identifier and RHS (right hand side) identifiers are called tokens.
LHS ::= RHS ...
You can provide alternatives with the vertical bar | "OR" symbol.
LHS ::= RHS1 ... { | RHS2 ... }
Is equivalent to:
LHS ::= RHS1 ...
LHS ::= RHS2 ...
You can use the | alternate on the end of one line or the start of another:
LHS ::= RHS1 ... |
RHS2 ...
LHS ::= RHS1 ...
| RHS2 ...
You can use ||= as a shorthand way of writing | between every letter of the RHS
HEX ||= ABCDEFabcdef0123456789
Is equivalent to:
HEX ::= A | B | C | D | ... | 8 | 9
This is useful for character grammars, so check out the -c option too.
Tokens
Tokens may be practically any string separated by whitespace. The "normal" identifier rules you might be familiar with in other languages do not apply here. For example 98* is a perfectly acceptable token even though it starts with a number and has a * in it.
If a token only appears on the right hand side (RHS) of the ::=, it is said to be a terminal token. If a token appears on the left hand side (LHS) and the RHS, then the token is said to be a non-terminal token. tacc automatically works this out.
It is conventional in grammar BNFs to make non terminals uppercase and terminals lowercase. This is not required or encouraged style in tacc, but feel free to go with the flow. You can use ::= or just = as a production operator. This document was written before = was allowed as an alternative and the author writes ::= mostly out of habit. Don't feel that you need to. There is no need to end statements with a ; as you see in some extended BNFs either, tacc uses line breaks as a delimiter. tacc wants the BNF syntax to be as natural and uncluttered with language syntax as possible.
A right hand side RHS may be optional, you can indicate this in tacc by using NULL
LHS ::= NULL
A token can be enclosed in quotes or you can start it with a backslash \ if it has special characters that might confuse tacc.
LHS ::= "NULL"
LHS ::= \NULL
OR ::= \|
Terminal Tokens
A terminal token may be a simple string or a regular expression in /slashes/
keyword ::= while
number ::= /[0-9]+/
Regular Expressions
tacc regular expressions are stock standard, 7 bit ASCII only. The tacc compiled lexer will recognise any number of regular expressions in parallel just as quickly as one.
The following tables can also be seen with tacc -RR for regex help.
|
regex |
Description |
Example |
|
c |
Any non special character c matches itself |
k matches k |
|
. |
matches any single character except \r \n and \0 |
. matches a, B, c, x, ... |
|
^ |
matches the start of a line |
^a matches lines that start with a |
|
$ |
matches the end of a line |
z$ matches lines that end in z |
|
\n \r \t |
matches \n newline, \r carriage return and \t tab |
\n matches \n |
|
\\ |
matches \ |
\\ matches \ |
|
\s |
matches special character s |
\. matches . |
|
\xHH |
matches hex character HH |
\x20 matches space |
|
[xyz0-9] |
matches characters and ranges in between [...] |
gr[ae]y[0-9] matches gray7 and grey9 |
|
[^xyz0-9] |
matches not (characters and ranges) in between [^...] |
[^A-Z] matches not uppercase |
|
[:class:] |
matches a standard class of characters (see below), must be used inside [...] |
[[:digit:]] matches a digit 0 to 9 |
|
a* |
matches 0 or more a's |
a* matches "", a, aa, aaa... |
|
a+ |
matches 1 or more a's |
a+ matches a, aa, aaa... |
|
a? |
matches 0 or 1 a's |
ab?c matches ac, abc, but not abbc |
|
a|b |
matches a or b, almost always used with (a|b) |
gr(ay|ey) matches gray and grey |
|
( ) |
delimits a sub-expression that you can apply * + ? to |
(ab)+ matches ab, abab, ababab, ... |
|
. means does NOT match -- any other
character means match | |
|
|
|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+-- 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001111111111111111111111111111 00000000001111111111222222222233333333334444444444555555555566666666667777777777888888888899999999990000000000111111111122222222 01234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567 |----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+----|----+-- |
|
[:class:] |
................................ !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~. |
|
none blank cr eol space cntrl digit xdigit lower upper alpha alnum word punct graph dot any notnull regord regres |
................................................................................................................................ .........Y......................S............................................................................................... ..........Y..Y.................................................................................................................. Y.........Y..Y.................................................................................................................. .........YYYYY..................S............................................................................................... YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY...............................................................................................Y ................................................0123456789...................................................................... ................................................0123456789.......ABCDEF..........................abcdef......................... .................................................................................................abcdefghijklmnopqrstuvwxyz..... .................................................................ABCDEFGHIJKLMNOPQRSTUVWXYZ..................................... .................................................................ABCDEFGHIJKLMNOPQRSTUVWXYZ......abcdefghijklmnopqrstuvwxyz..... ................................................0123456789.......ABCDEFGHIJKLMNOPQRSTUVWXYZ......abcdefghijklmnopqrstuvwxyz..... ................................................0123456789.......ABCDEFGHIJKLMNOPQRSTUVWXYZ...._.abcdefghijklmnopqrstuvwxyz..... .................................!Y#$%&'()*+,-Y/..........:;<=>?@..........................[\]^_`..........................{|}~. .................................!Y#$%&'()*+,-Y/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~. ................................S!Y#$%&'()*+,-Y/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~. .YYYYYYYYY.YY.YYYYYYYYYYYYYYYYYYS!Y#$%&'()*+,-Y/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~Y YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYS!Y#$%&'()*+,-Y/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~Y .YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYS!Y#$%&'()*+,-Y/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~Y .YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYS!Y#.%&'....,../0123456789.;<=>.@ABCDEFGHIJKLMNOPQRSTUVWXYZ...._`abcdefghijklmnopqrstuvwxyz{.}~. Y...................................$...()*+.-Y...........:....?...........................[\]^.............................|... |
||= and /regexes/
It might seem a first glance that ||= expressions could be replaced by a regular expressions, and in some cases they can, but they are very different.
A /regex/ is a single token that matches some input during lexical scanning of your input.
||= makes multiple tokens, all of which are matched and returned separately by the lexer.
For example this regex returns a single token number for digit, for which the argv[] could be any character '0'-'9':
digit ::= /[0-9]/
And this one returns a separate token for each digit 0, 1, 2, ... , 9 and the argv[] would be '0', '1', '2', ... , '9'.
digit ||= 0123456789
tacc grammar
This is the actual grammar used to build tacc's BNF parser:
//
// tacc bnf grammar
//
goal ::= grammar
grammar ::= statement | grammar statement
statement ::= production EOL |
production eol code |
include_tag eol code |
eol
production ::= LHEX prodop RHEX |
LHEX prodop eol RHEX
LHEX ::= LHS | NULL
prodop ::= \::= | \= | \| | \||=
RHEX ::= RHS |
RHEX \| RHS |
RHEX \| eol RHS
RHS ::= regex_token | RHS regex_token
LHS ::= plain_token
regex_token ::= token | regex
plain_token ::= token
token ::= word | quoted_text | escaped_word
include_tag ::= word
EOL ::= eol | EOS
code ::= /{([^[:eol:]]|[[:eol:]][^}])*[[:eol:]]}/
regex ::= /\/([^\\[:eol:]\/]|\\.)*\//
escaped_word ::= /\\[^[:space:]]+/
quoted_text ::= /"([^\\[:eol:]\"]|\\.)*"|'([^\\[:eol:]\']|\\.)*'/
word ::= /[^[:space:]]+/
eol ::= /[[:space:]]*(\/\/[^[:eol:]]*)?[[:eol:]]+[[:blank:]]*([[:space:]]*(\/\/[^[:eol:]]*)?[[:eol:]]+[[:blank:]]*)*/
tacc regex grammar
And this is the grammar used to build the regular expression parser:
goal ::= regex
regex ::= alternation
alternation ::= concatenation | alternation \| concatenation
concatenation ::= quantified | concatenation quantified
quantified ::= meta | meta * | meta + | meta ?
meta ::= character | ^ | $ | . | list | ( regex )
list ::= matching_list | non_matching_list
matching_list ::= [ list_spec ]
non_matching_list ::= [ ^ list_spec ]
list_spec ::= list_character | list_spec list_character
list_character ::= range | class | character
range ::= character - character
class ::= [ : class_name : ]
class_name ::= literal_string
literal_string ::= identifier_character | literal_string identifier_character
character ::= escape_sequence | hex_character | literal_character
escape_sequence ::= \\ escaped_character
hex_character ::= \\ x hex_digit hex_digit
literal_character ::= identifier_character | ordinary_character
escaped_character ::= reserved_character | slash_character | ordinary_character
all_characters
{
||= ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz _ 0123456789 !@#$%^&+-*.,:;?=~ () [] {} <> \/ \\ \| \" ' ` " " \t \r \n
}
identifier_character ||= ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz _ 0123456789
ordinary_character ||= !@# % & , ; =~ {} <> \/ \" ' ` " "
reserved_character ||= $ ^ +-* . : ? () [] \\ \|
slash_character ||= trn
hex_digit ||= 0123456789 ABCDEF abcdef
tacc -options
tacc compile -options you will use
tacc with no options
Simply prints a short usage:
> tacc
tacc compiles an extended BNF grammar to (LA)LR(1) parser in C++ or Java.
usage: tacc [-gtpxsvlcdy] grammar.bnf [-o {parser.cpp|parser.java}]
[{-m template_file | -M internal_template_name}]
[-GWTV-?]
tacc -I can interpret the generated output C++ file.
usage: tacc -I interpret_source_file.cpp { -f input_file | input_string... }
[-xrtasnlpvewb]
[-GWTV-?]
Use tacc -? for more help on BNF compiler mode
Use tacc -I? for more help on C++ interpreter mode
-? Help
Simply prints all the -options:
> tacc -?
usage: tacc [-gtpxsvlcdy] grammar.bnf [-o {parser.cpp|parser.java}]
[{-m template_file | -M internal_template_name}]
[-GWTV-?]
tacc compiles a simple BNF like grammar and outputs (LA)LR(1) parser source
code in C++ or Java with a built in lexical scanner. You can compile the
resultant source code immediately with a C++ or Java compiler or you can use
tacc -I to interpret the source file.
See tacc -I? for more help on interpreter mode.
-options:
-g print goal token
-t print tokens
-p print productions
-x print transitions
-s print states
-i print input tokens (more useful with -s)
-v verbose, equivalent to -gtpxsi
-l construct an LALR(1) parser instead of an LR(1) parser
-c ensure token ids for single character token names = ascii of the character
-d list available internal templates
-k generate a context aware lexer
-y if a state's actions are all the same reduction, do it on any token
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-RR help on regexes and regex classes.
-V Version
-- Stop -option parsing
-? This help message
Examples:
tacc regex.bnf -o regex.cpp -> compile regex.bnf to regex.cpp
tacc -I regex.cpp -pp "a*b+c?(this|that)" -> run the interpreter on regex.ccp with input string
tacc regex.bnf -o regex.java -> compile regex.bnf to regex.java
tacc -l regex.bnf -o regex.cpp -> compile regex.bnf as LALR (better)
tacc -d -> list available templates
tacc -M default -o template.cpp -> output the default template to template.cpp
-l construct an LALR(1) parser instead of an LR(1) parser
It is fairly common for grammars to generate a lot of internal states that are very similar. The -l option constructs the LR(1) parser as normal and then tries to merge similar states to what is known as an LALR(1) parser. The LALR(1) parser is generally smaller than the LR(1) parser with almost no drawbacks, so it is generally a good idea to use -l. The drawbacks are that it takes tacc more time to build your parser and, if you give the generated parser incorrect input, that it may internally loop a few extra times before working out that the input is incorrect. The LALR(1) generated parser is still correct in every way though.
(Unlike some other parser generators, tacc will not generate any sort of mysterious conflicts when generating LALR(1) automatons, so you can use -l with confidence.)
I like to think of the -l as the "optimised" compile of your grammar.
Here it is being used to compile the regex grammar and reduces the number of states in the automaton from 686 to 176, which is pretty significant:
> tacc -l regex.bnf -o regex.cpp
tacc: reading grammar file: regex.bnf
tacc: checking productions
tacc: building automation
tacc: LALR merging states
tacc: building lexer
Parser States: 686 - 510 merged = 176
Lexical States: 2
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1)
tacc: using internal template: default (vogue)
tacc: output file is: regex.cpp
-t -g print tokens
After you generate a parser with tacc, you can add semantic actions to your code (see Introduction). The only tokens that are actually delivered to your semantic code are terminal tokens. That is, tokens that appear on the right hand side (RHS) of the ::=, but not on the left hand side (LHS). Usually it is pretty obvious which tokens are terminal or not, but should you be wanting a list of tokens and how they are categorised, then use -t.
-g simply prints the goal token, which is the first token encountered in the BNF file.
> cat identifiers.bnf
GOAL ::= ids
ids ::= id | ids id
id ::= /[A-Za-z_][A-Za-z_0-9]*/
> tacc -tg identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Goal
Goal is GOAL
Tokens
0. virtual not_null terminal - plain UNKNOWN
1. virtual not_null terminal - plain ERROR
2. virtual not_null terminal - plain EOS
3. virtual not_null terminal - plain ANY
4. virtual nullable terminal - plain NULL
5. virtual not_null terminal - plain START
6. goal not_null product pure plain GOAL
7. real not_null product pure plain ids
8. real not_null product prime plain id
9. real not_null terminal input regex /id/ /[A-Za-z_][A-Za-z_0-9]*/
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
As you can see, tacc reserves some virtual tokens that are used by the parser. It is not necessary to understand what they are or what they do, but it is instructive to know what they are for:
|
token |
Description |
|
UNKNOWN |
in a list of tokens, the UNKNOWN token (usually 0) is placed on the end for human readability, it is not used by tacc specifically |
|
ERROR |
is the token returned by the lexer when none of your terminal tokens matched the input string |
|
EOS |
end of string is the last token of any input, it is supplied and handled automatically in tacc |
|
ANY |
a special token used with -y that means if all the reductions in the state are the same, do it on any token. See option -y. |
|
NULL |
the token that means it could be nothing, as in no input at all. eg prefix ::= + | - | NULL |
|
START |
simply marks the place in the token table where real (as opposed to virtual) tokens start, it is not used by tacc specifically |
tacc compile -options you might use
-p print productions
Printing productions really just lists your .bnf file with tacc's categorisation.
> tacc -p identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Productions
1. nulls: 0 reachable terminating GOAL ::= ids
2. nulls: 0 reachable terminating ids ::= id
3. nulls: 0 reachable terminating ids ::= ids id
4. nulls: 0 reachable terminating id ::= /[A-Za-z_][A-Za-z_0-9]*/
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
-x print transitions
Printing transitions displays the full pushdown automaton and shows exactly what the parser would do when it parses your input string.
> tacc -x identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Transitions
state 1 on ids ---> 2
state 1 on id ---> 3
state 1 on /id/ ---> 4
state 2 on EOS _o-> GOAL ::= ids
state 2 on id ---> 5
state 2 on /id/ ---> 4
state 3 on EOS /id/ _o-> ids ::= id
state 4 on EOS /id/ _o-> id ::= /[A-Za-z_][A-Za-z_0-9]*/
state 5 on EOS /id/ _o-> ids ::= ids id
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
When tacc is compiling your grammar, it makes a states which indicate where the parser is currently and transitions that indicate where it might go, given particular a particular token. Understanding transitions requires some knowledge of pushdown automata, so take a look at the section on Parsing Basics. Also see tacc -I -x for a walkthrough of what transitions look like when the parser is executing.
-m -M -d Using Templates
If you don't like the default template that tacc uses, you can use your own, or modify the one tacc uses.
You can list the templates built in to tacc and export them for perusal like this:
> tacc -d
Name Ext Default Description
-------- ---- ------- ----------------------------------------------------------------
classic cpp No Older C++ template with no real redeeming features.
sienna cpp No C++ template generated around tacc 4.03. Still good.
vogue cpp Yes C++ template generated from the tacc source code.
jive java No Simple Java template for tiny grammars.
juke java Yes Java template with parser tables in *.joos.dat files.
cup cup Yes Convert to CUP parser format. Not perfect.
default * * Matches a default template above by output file extension.
> tacc -M default -o template.cpp
Now you can edit template.cpp and use it with tacc -m
> tacc -m template.cpp identifiers.bnf -o identifiers.cpp
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc: using template file: template.cpp
tacc: output file is: identifiers.cpp
tacc compile -options you won't use
-s print states
Printing states shows the internals of the compile process. It is unlikely that you will want this, but it can be instructive if you want to learn how to build a pushdown state automaton from a BNF grammar. It can sometimes be useful when debugging grammars, but most of the time it outputs just too much stuff.
> tacc -s identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
States
---- START ---> state 1
| 1. GOAL ::= . ids ---> 2 EOS
| 3. ids ::= . ids id ---> 2 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 2. ids ::= . id ---> 3 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- ids ---> state 2
| 1. GOAL ::= ids . _o-> -1 EOS
| 3. ids ::= ids . id ---> 5 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- id ---> state 3
| 2. ids ::= id . _o-> -2 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- /id/ ---> state 4
| 4. id ::= /[A-Za-z_][A-Za-z_0-9]*/ . _o-> -4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- id ---> state 5
| 3. ids ::= ids id . _o-> -3 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
Creating an automaton by hand is pretty tedious, but if you want to learn how, see the section on Parsing Basics.
There is no need whatsoever to understand how tacc builds an automaton to use tacc.
-c character tokens = character ascii
If you want to get hardcore with your parsing, you might want to consider your input stream one character at a time. So instead of:
keyword ::= while
You would write:
keyword ::= w h i l e
If you are doing it one character at a time, you can greatly simplify the lexical scanner from the standard regex matcher to one that simply reads one character. And to make things even simpler, why not make the token number equal to the ascii of the character as well? This is what -c does. It makes all of the token numbers for single characters equal to the ascii of the character.
Even though it makes the lexer lightning fast, it puts more work on the parser (and you writing the BNF too).
tacc didn't always have a fancy regex lexer. tacc's regex lexer was built with tacc -c.
-y if a state's actions are all the same reduction, do it on any token
Most of the time, if your state has only one reduction, it will do that reduction on every token. -y reduces all those to one reduction on the special single any token.
The upside of -y is that it slightly speeds up finding what action to do when you are in state S with token T and makes the parser slightly smaller.
The downside of -y is that it is a relaxation of your grammar, meaning it could accept input that it should have rejected. This would be pretty rare, most of the time it would do a reduce based on any that it should not have done and then whatever the real token is coming up next would likely not be able to be shifted and it would stop anyway. Even if it did continue at that stage, you can deal with it in your semantics. -y is not for beginners.
The -y process in tacc is done during the output of the .cpp file, so you won't see it with -s, but if you go through the C++ output tables (not recommended), effectively it changes this:
> tacc -s identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
States
---- START ---> state 1
| 1. GOAL ::= . ids ---> 2 EOS
| 3. ids ::= . ids id ---> 2 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 2. ids ::= . id ---> 3 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- ids ---> state 2
| 1. GOAL ::= ids . _o-> -1 EOS
| 3. ids ::= ids . id ---> 5 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- id ---> state 3
| 2. ids ::= id . _o-> -2 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- /id/ ---> state 4
| 4. id ::= /[A-Za-z_][A-Za-z_0-9]*/ . _o-> -4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- id ---> state 5
| 3. ids ::= ids id . _o-> -3 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
To this (NOTE! FAKED OUTPUT!):
> tacc -sy identifiers.bnf
tacc: reading grammar file: identifiers.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
States
---- START ---> state 1
| 1. GOAL ::= . ids ---> 2 EOS
| 3. ids ::= . ids id ---> 2 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 2. ids ::= . id ---> 3 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- ids ---> state 2
| 1. GOAL ::= ids . _o-> -1 EOS
| 3. ids ::= ids . id ---> 5 EOS /[A-Za-z_][A-Za-z_0-9]*/
| 4. id ::= . /[A-Za-z_][A-Za-z_0-9]*/ ---> 4 EOS /[A-Za-z_][A-Za-z_0-9]*/
--------------------
---- id ---> state 3
| 2. ids ::= id . _o-> -2 ANY Note! faked output!
--------------------
---- /[A-Za-z_][A-Za-z_0-9]*/ ---> state 4
| 4. id ::= /[A-Za-z_][A-Za-z_0-9]*/ . _o-> -4 ANY Note! faked output!
--------------------
---- id ---> state 5
| 3. ids ::= ids id . _o-> -3 ANY Note! faked output!
--------------------
Parser States: 5
Lexical States: 3
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc -I interpreter and -options
tacc -I interpreter
tacc can interpret its output C++ or Java file with the same results as if you had compiled and executed it.
tacc is not a general C++ or Java interpreter, it just knows the structure of its own output. So this means it can't execute code put in { ... } in your bnf.
The tacc interpreter is very useful when developing grammars because you can immediately do a test parse without compiling the output.cpp file. In fact you can play with grammars and LR parsing without a C++ compiler at all.
The built in lexer means there is no need for any extra tools to build a lexical scanner. The default lexer works out of the box and is flexible enough not to require any modifications to work with your input.
The parser engine and options for the interpreter are identical to the compiled version since they are built from same source.
It is difficult to explain just how good this is compared to other parsing tools if you haven't done this sort of thing before.
Using the tacc -I interpreter for C++
Just use tacc -I with the file.cpp file you get from tacc file.bnf:
> tacc -I identifiers.cpp "this and that"
tacc: string accepted
> tacc -I identifiers.cpp "this then 9fail"
tacc: Error: Unrecognised input "9fail"
Line 1. this then 9fail
^^^^^
Nice, but not very informative on what is going on. But there are options.
tacc -I interpreter -options you will use
-I? Help
-I? Simply prints all the -options:
> tacc -I?
usage: tacc -I interpret_source_file.cpp { -f input_file | input_string... }
[-xrtasnlpvewb]
[-GWTV-?]
tacc -I interprets a source code file created from a tacc grammar.bnf
tacc -I is NOT a general C++ or Java interpreter, it just knows the structure
of tacc generated source code and reads the tables from the cpp files it created.
The parser engine and options for the interpreter are identical to the compiled
version since they are built from same source.
-options:
-f infile
-x print transitions
-r print reductions
-t print tokens as they are read (-ttt... -K = max t's)
-a print terminal args with reductions
-s print top of parse tree stack with reductions (needs -p)
-n only print reductions that have terminal args
-l print lookahead with reductions
-p print parse tree, -pp print fancier parse tree
-v verbose, equivalent to -alrpptx
-e suppress expecting... output
-k don't use context aware lexing
-w don't ignore end of lines (\n, \f) (\r is always ignored)
-ww don't ignore any whitespace (\n \f \v \t ' ') (\r is always ignored)
-b print the BNF source for this program
-B print the input string or filename
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-RR help on regexes and regex classes.
-V Version
-- Stop -option parsing
-? This help message
Examples:
tacc regex.bnf -o regex.cpp -> compile regex.bnf to regex.cpp
tacc -I regex.cpp -pp "a*b+c?(this|that)" -> run the interpreter on regex.ccp with input string
-I -t print tokens as they are read
-t tells the lexer to print tokens when they are read. It is good to see that your terminal tokens are being recognised:
> tacc -I identifiers.cpp -t "this and that"
lex: next token is {9 /id/ = "this"}
lex: next token is {9 /id/ = "and"}
lex: next token is {9 /id/ = "that"}
lex: next token is {2 EOS = ""}
tacc: string accepted
The output format is { token_number terminal_token_plain_or_regex = "input that matched" }
The more -t's you give, the more info it reports on each token, up until an insane 12 t's (or use -K which is short for the max number of -t's) when it prints a ridiculous amount of debug as it steps through the regular expression matcher internals (not recommended).
Here is a more sensible -tt which prints neat little markers showing where it found the token on the input line (read so far).
> tacc -I identifiers.cpp -tt "this and that"
lex: next token is {9 /id/ = "this"}
1: this
^^^^
lex: next token is {9 /id/ = "and"}
1: this and
^^^
lex: next token is {9 /id/ = "that"}
1: this and that
^^^^
lex: next token is {2 EOS = ""}
1: this and that
^
tacc: string accepted
-I -r -a -l -n print reductions
-r tells the parser to print reductions as they are recognised:
> tacc -I identifiers.cpp -r "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
2: ids ::= id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
3: ids ::= ids id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
3: ids ::= ids id
1: GOAL ::= ids
tacc: string accepted
-ra tells the parser to print reductions and the arguments that would be given to your semantic function. So when you were writing some semantic code to go with this grammar, you can see which reduction is being executed and what arguments you would get when they are:
> tacc -I identifiers.cpp -ra "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "this"
3: ids ::= id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "and"
2: ids ::= ids id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "that"
2: ids ::= ids id
1: GOAL ::= ids
tacc: string accepted
The more -a's you give, the more info it reports on each argument:
> tacc -I identifiers.cpp -raa "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "this", argt[0]->token = 9}
3: ids ::= id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "and", argt[0]->token = 9}
2: ids ::= ids id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "that", argt[0]->token = 9}
2: ids ::= ids id
1: GOAL ::= ids
tacc: string accepted
> tacc -I identifiers.cpp -raaa "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "this", argt[0]->token = 9, regex_tokens[9] = /id/}
3: ids ::= id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "and", argt[0]->token = 9, regex_tokens[9] = /id/}
2: ids ::= ids id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: {argv[0] = "that", argt[0]->token = 9, regex_tokens[9] = /id/}
2: ids ::= ids id
1: GOAL ::= ids
tacc: string accepted
> tacc -I identifiers.cpp -raaaa "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals:
[0] = {
argv[0] = "this"
argt[0] = {
->token = 9
string_tokens[9] = /[A-Za-z_][A-Za-z_0-9]*/
regex_tokens[9] = /id/
->line_start = 1, ->start = 0, ->line_end = 1, ->end = 3
}
}
3: ids ::= id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals:
[0] = {
argv[0] = "and"
argt[0] = {
->token = 9
string_tokens[9] = /[A-Za-z_][A-Za-z_0-9]*/
regex_tokens[9] = /id/
->line_start = 1, ->start = 5, ->line_end = 1, ->end = 7
}
}
2: ids ::= ids id
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals:
[0] = {
argv[0] = "that"
argt[0] = {
->token = 9
string_tokens[9] = /[A-Za-z_][A-Za-z_0-9]*/
regex_tokens[9] = /id/
->line_start = 1, ->start = 9, ->line_end = 1, ->end = 12
}
}
2: ids ::= ids id
1: GOAL ::= ids
tacc: string accepted
-rl tells the parser to print reductions and the current lookahead token. The lookahead token is half the reason "why" this reduction was done (the other half is because we have already read the RHS of the reduction) It is not all that useful:
> tacc -I identifiers.cpp -rl "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . and
2: ids ::= id . and
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . that
3: ids ::= ids id . that
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . EOS
3: ids ::= ids id . EOS
1: GOAL ::= ids . EOS
tacc: string accepted
-ran tells the parser to only print reductions that have terminal arguments. Almost always used with -a so you can see the terminal args as well. This is useful if you have a grammar with a deep reduction parse tree but with few that actually handle terminal tokens. This is seen in expression calculators that have lots of layers of precedence rules.
> tacc -I identifiers.cpp -ran "this and that"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "this"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "and"
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
terminals: argv[0] = "that"
tacc: string accepted
-I -p -pp print (pretty) parse tree
-p tells the parser to print a parse "tree". -pp prints the same thing, but on multiple lines, so it looks a bit more like a tree. -p does some guesswork on how you want the parse tree to look and doesn't always get it right, so it is always a parse tree, but sometimes it is not pretty.
> tacc -I identifiers.cpp -pp "this and that"
Parse Tree:
[thisandthat]
[thisandthat]
tacc: string accepted
It looks a little better with a calculator type parser. Here is a calculator that has been compiled and has semantics to actually do the calculation. Interpreted or compiled, each way has the same -options:
> calc -pp "(8 + 2 * 3) / (1 + 9)"
Parse Tree:
[[[8+[2*3]]()]/[[1+9]()]]
[ / ]
[ ()] [ ()]
[8+ ] [1+9]
[2*3]
1.4
tacc -I interpreter -options you might use
-I -b print source bnf
-b prints the .bnf source that was used to make the parser. But not in the original format, so it is not that exciting. It is useful to remind yourself exactly what (version of your) grammar was used to build this parser. And it would be really useful if you had lost your .bnf.
C:\Trev\Projects\tacc\Debug>tacc -I identifiers.cpp -b
GOAL ::= ids
ids ::= id
ids ::= ids id
id ::= /[A-Za-z_][A-Za-z_0-9]*/
-I -x print transitions
-x prints transitions between states as they occur during parsing. Are you ready for this?
> tacc -I identifiers.cpp -txal "this and that"
lex: next token is {9 /id/ = "this"}
state 1 on 9 /id/ ---> state 4
lex: next token is {9 /id/ = "and"}
state 4 on 9 /id/ _o-> state 1 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . and
terminals: argv[0] = "this"
state 1 on 8 id ---> state 3
state 3 on 9 /id/ _o-> state 1 reduce 3: ids ::= id . and
state 1 on 7 ids ---> state 2
state 2 on 9 /id/ ---> state 4
lex: next token is {9 /id/ = "that"}
state 4 on 9 /id/ _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . that
terminals: argv[0] = "and"
state 2 on 8 id ---> state 5
state 5 on 9 /id/ _o-> state 1 reduce 2: ids ::= ids id . that
state 1 on 7 ids ---> state 2
state 2 on 9 /id/ ---> state 4
lex: next token is {2 EOS = ""}
state 4 on 2 EOS _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . EOS
terminals: argv[0] = "that"
state 2 on 8 id ---> state 5
state 5 on 2 EOS _o-> state 1 reduce 2: ids ::= ids id . EOS
state 1 on 7 ids ---> state 2
state 2 on 2 EOS _o-> state 1 reduce 1: GOAL ::= ids . EOS
tacc: string accepted
States are built during the compile of the grammar.
Transitions come in two different actions and are printed like this:
in_state S on some_token shift_action---> to_state_N
in_state S on some_token reduce_action_o-> to_state_N reduce some_production
A shift action accepts a token and moves the parser to another state.
A reduce action recognises a production in the grammar and consumes shifted tokens on the right hand side (RHS) of the production, replacing them with the token on the left hand side (LHS) of the production. It also returns to a prior state, but now with the LHS as the next token.
So this grammar compiles to 5 states. To recognise the string input, we boot the parser by pushing state 1 on the state stack. We also call this in_state 1, but it really means the top of the state stack is 1.
The input string is "this and that", the parser will need some input, so it calls the lexer:
lex: next token is {9 /id/ = "this"}
The lexer matched the string "this" to the regex terminal token number 9, which is a regular expression /[A-Za-z_][A-Za-z_0-9]*/ or /id/ for short, since id ::= /[A-Za-z_][A-Za-z_0-9]*/. tacc uses a short version of regexes if the production is of the form something ::= /one_regex/ to improve readability.
As tokens are read, they are pushed on to the token stack. The top of the token stack is known as the on_token. (Some call this the lookahead token, and in this case, it is. tacc only calls a token the lookahead token when it is a terminal. Later on you will see the on_token can change, but he lookahead will stay the same.) We say the on_token is 9 /id/ = "this".
In general parsing goes, if we are in state S, on token K then do action. It is very deterministic and at its heart it is quite simple. All the grunt work for parsing is done up front when you compile your grammar. The execution of the parser is straightforward really.
To parse the string the find the transition that matches in_state, on_token pair. In this case we are in_state 1, on_token 9 /id/ = "this":
state 1 on 9 /id/ ---> state 4
This transition tells us the action will be a ---> shift action to state 4. It is called a shift action, because the token is shifted to the left of an imaginary parsing cursor (often represented as a dot . character). Or the cursor is shifted to the right through the string if you prefer. Or the whole string is shifted to the left. All are correct. The shift action pushes the 4 on to the state stack, so now the in_state is 4.
Because of this shift action, and because the shifted token was a terminal, we will read the next token:
lex: next token is {9 /id/ = "and"}
The lexer matched the string "and" to /id/ and pushes it on to the token stack, "and" becomes the on_token.
Now we are in_state 4, on_token /id/ = "and", so we find the matching transition:
state 4 on 9 /id/ _o-> state 1 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . and
This transition tells us the action will be a _o-> reduce action with the production, or really now, the reduction id ::= /[A-Za-z_][A-Za-z_0-9]*/ (That _o-> is supposed to look like a curly arrow with a loop in it. It is the way the author draws a reduction on a state diagram)
The reduction action wants us to take tokens that we have read matching the right hand side (RHS) of the production and change them into the token on the left hand side (LHS).
This corresponds to the tokens below the on_token on the token stack. In this case it is 1 token, "this".
The parser calls your semantic action for the reduction id ::= /[A-Za-z_][A-Za-z_0-9]*/ with the argc = 1 and argv = "this".
terminals: argv[0] = "this"
Then argc elements are popped off the token stack and the state stack. (Most of the time it is argc, but NULLs can make it more difficult to predict, so tacc precalculates the exact number to pop off the state stack for each reduction during compilation) And the LHS token = id is pushed onto the stack and becomes the on_token.
The top of the state stack, or in_state is now back to 1 and this time the on_token is id. Find the matching transition:
state 1 on 8 id ---> state 3
And so on...
Another way to look at this is to imagine the parse cursor going through the string, reducing input as it goes.
(Unfortunately tacc can't produce this output since 1. it doesn't read that far ahead, and 2. it doesn't bother to keep non-terminals, they are implied by the state you are in):
. this and that state 1 on 9 /id/ ---> state 4
this . and that state 4 on 9 /id/ _o-> state 1 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
. id and that state 1 on 8 id ---> state 3
id . and that state 3 on 9 /id/ _o-> state 1 reduce 2: ids ::= id
. ids and that state 1 on 7 ids ---> state 2
ids . and that state 2 on 9 /id/ ---> state 4
ids and . that state 4 on 9 /id/ _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
ids . id that state 2 on 8 id ---> state 5
ids id . that state 5 on 9 /id/ _o-> state 1 reduce 3: ids ::= ids id
. ids that state 1 on 7 ids ---> state 2
ids . that state 2 on 9 /id/ ---> state 4
ids that . state 4 on 2 EOS _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/
ids . id state 2 on 8 id ---> state 5
ids id . state 5 on 2 EOS _o-> state 1 reduce 3: ids ::= ids id
. ids state 1 on 7 ids ---> state 2
ids . state 2 on 2 EOS _o-> state 1 reduce 1: GOAL ::= ids
. GOAL
tacc -I interpreter -options you won't use
-I -s -p print the top of the parse tree stack
-s prints the top of the -p parse tree stack stx.top. I thought it would be really good, but it turned out not so great. Use -xrpls for best effect.
> tacc -I identifiers.cpp -xrpls "this and that"
state 1 on 9 /id/ ---> state 4
state 4 on 9 /id/ _o-> state 1 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . and
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . and
stx.top: this
state 1 on 8 id ---> state 3
state 3 on 9 /id/ _o-> state 1 reduce 3: ids ::= id . and
3: ids ::= id . and
stx.top: this
state 1 on 7 ids ---> state 2
state 2 on 9 /id/ ---> state 4
state 4 on 9 /id/ _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . that
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . that
stx.top: and
state 2 on 8 id ---> state 5
state 5 on 9 /id/ _o-> state 1 reduce 2: ids ::= ids id . that
2: ids ::= ids id . that
stx.top: [thisand]
state 1 on 7 ids ---> state 2
state 2 on 9 /id/ ---> state 4
state 4 on 2 EOS _o-> state 2 reduce 4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . EOS
4: id ::= /[A-Za-z_][A-Za-z_0-9]*/ . EOS
stx.top: that
state 2 on 8 id ---> state 5
state 5 on 2 EOS _o-> state 1 reduce 2: ids ::= ids id . EOS
2: ids ::= ids id . EOS
stx.top: [thisandthat]
state 1 on 7 ids ---> state 2
state 2 on 2 EOS _o-> state 1 reduce 1: GOAL ::= ids . EOS
1: GOAL ::= ids . EOS
stx.top: [thisandthat]
Parse Tree:
[thisandthat]
tacc: string accepted
-I -w -ww turn off automatic whitespace control
-w controls how tacc controls whitespace. Dealing with whitespace is a fairly tedious thing in parsing. Fortunately tacc does this automatically for you. And most of the time you want this, but if you want to take control, build your grammar with your whitespace tokens and run tacc with:
-w don't ignore end of lines (\n, \f) (\r is always ignored)
-ww don't ignore any whitespace (\n \f \v \t ' ') (\r is always ignored)
If you want these permanently set, you can call parser p.whitespace_control(int wflag) somewhere.
There are many ways to deal with whitespace. You can deal with it like it was a separator or treat them like "blank" ids.
Let's modify the identifiers.bnf grammar to handle whitespace as if they could be "blank" ids:
> cat identifiers.whitespace.bnf
GOAL ::= words
words ::= word | words word
word ::= id | ws
id ::= /[A-Za-z_][A-Za-z_0-9]*/
ws ::= /[[:space:]]+/
Compile the grammar with tacc:
> tacc identifiers.whitespace.bnf -o identifiers.whitespace.cpp
tacc: reading grammar file: identifiers.whitespace.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 8
Lexical States: 4
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1) but is LR(0) if you allow shifting of the EOS token
tacc: using internal template: default (vogue)
tacc: output file is: identifiers.whitespace.cpp
Run tacc -I with -ww to stop it from automatically handling whitespace:
> tacc -I identifiers.whitespace.cpp -ww -tr "this and that"
lex: next token is {11 /id/ = "this"}
lex: next token is {12 /ws/ = " "}
6: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: word ::= id
2: words ::= word
lex: next token is {11 /id/ = "and"}
7: ws ::= /[[:space:]]+/
5: word ::= ws
3: words ::= words word
lex: next token is {12 /ws/ = " "}
6: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: word ::= id
3: words ::= words word
lex: next token is {11 /id/ = "that"}
7: ws ::= /[[:space:]]+/
5: word ::= ws
3: words ::= words word
lex: next token is {2 EOS = ""}
6: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: word ::= id
3: words ::= words word
1: GOAL ::= words
identifiers.whitespace: string accepted
The trouble with that approach is that you have to deal with a word possibly being blank. And even though it is pretty easy in this case, it would be nice to make the parser do the work of delivering "pure" ids to you. This approach to the grammar treats whitespace as an optional separator:
> cat identifiers.whitesep.bnf
GOAL ::= expr
expr ::= ws_opt ids ws_opt
ids ::= id | ids ws_opt id
ws_opt ::= ws | NULL
id ::= /[A-Za-z_][A-Za-z_0-9]*/
ws ::= /[[:space:]]+/
Compile the grammar with tacc:
> tacc identifiers.whitesep.bnf -o identifiers.whitesep.cpp
tacc: reading grammar file: identifiers.whitesep.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Parser States: 12
Lexical States: 4
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(1)
tacc: using internal template: default (vogue)
tacc: output file is: identifiers.whitesep.cpp
Run tacc -I with -ww to stop it from automatically handling whitespace. This time, when an id is recognised and delivered to your semantic function, it won't be blank:
> tacc -I identifiers.whitesep.cpp -ww -tr "this and that"
lex: next token is {12 /id/ = "this"}
6: ws_opt ::= NULL
lex: next token is {13 /ws/ = " "}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
3: ids ::= id
lex: next token is {12 /id/ = "and"}
8: ws ::= /[[:space:]]+/
5: ws_opt ::= ws
lex: next token is {13 /ws/ = " "}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: ids ::= ids ws_opt id
lex: next token is {12 /id/ = "that"}
8: ws ::= /[[:space:]]+/
5: ws_opt ::= ws
lex: next token is {2 EOS = ""}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: ids ::= ids ws_opt id
6: ws_opt ::= NULL
2: expr ::= ws_opt ids ws_opt
1: GOAL ::= expr
identifiers.whitesep: string accepted
Both these grammars have been written in such a way that they also work with automatic whitespace left on. There is no need to try to do that, I just did it for fun:
> tacc -I identifiers.whitesep.cpp -tr "this and that"
lex: next token is {12 /id/ = "this"}
6: ws_opt ::= NULL
lex: next token is {12 /id/ = "and"}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
3: ids ::= id
6: ws_opt ::= NULL
lex: next token is {12 /id/ = "that"}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: ids ::= ids ws_opt id
6: ws_opt ::= NULL
lex: next token is {2 EOS = ""}
7: id ::= /[A-Za-z_][A-Za-z_0-9]*/
4: ids ::= ids ws_opt id
6: ws_opt ::= NULL
2: expr ::= ws_opt ids ws_opt
1: GOAL ::= expr
identifiers.whitesep: string accepted
A topic related to whitespace control is handling the end of string. The end of string token EOS can be used in your grammar as if it was a real character if necessary.
-I -e suppress expecting... output
-e When tacc is parsing input, if it receives an unexpected token, it prints an error message. Then it lists all the tokens that it was expecting. Sometimes this is nice, but a lot of times it is a massive list of 99% of all possible tokens. -e suppresses the listing of all the expected possible tokens.
For example:
> cat expecting.bnf
GOAL ::= count
count ::= one two three
Compile with tacc and run it with some wrong input:
> tacc -I expecting.cpp "one three"
tacc: Error: Unexpected input token: three
1: one three
^^^^^
found: three
expecting: two
Now if you run it with -e, it won't show the expecting bit:
> tacc -I expecting.cpp "one three" -e
tacc: Error: Unexpected input token: three
1: one three
^^^^^
Note that this is a different error to the one you get if you supply input that isn't recognised as a token:
> tacc -I expecting.cpp "one four" -e
tacc: Error: Unrecognised input "four"
1: one four
^^^^
tacc experimental -options
tacc -?? Full disclosure of options
tacc -?? Will display normal help plus experimental and undocumented options and usage. Needless to say the experimental stuff is not guaranteed to do anything useful. It is mostly for debugging and regression testing.
> tacc -??
usage: tacc [-gtpxsvlcdy] grammar.bnf [-o {parser.cpp|parser.java}]
[{-m template_file | -M internal_template_name}]
[-GWTV-?]
tacc compiles a simple BNF like grammar and outputs (LA)LR(1) parser source
code in C++ or Java with a built in lexical scanner. You can compile the
resultant source code immediately with a C++ or Java compiler or you can use
tacc -I to interpret the source file.
See tacc -I? for more help on interpreter mode.
-options:
-g print goal token
-t print tokens
-p print productions
-x print transitions
-s print states
-i print input tokens (more useful with -s)
-v verbose, equivalent to -gtpxsi
-l construct an LALR(1) parser instead of an LR(1) parser
-c ensure token ids for single character token names = ascii of the character
-d list available internal templates
-k generate a context aware lexer
-y if a state's actions are all the same reduction, do it on any token
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-RR help on regexes and regex classes.
-V Version
-- Stop -option parsing
-? This help message
Examples:
tacc regex.bnf -o regex.cpp -> compile regex.bnf to regex.cpp
tacc -I regex.cpp -pp "a*b+c?(this|that)" -> run the interpreter on regex.ccp with input string
tacc regex.bnf -o regex.java -> compile regex.bnf to regex.java
tacc -l regex.bnf -o regex.cpp -> compile regex.bnf as LALR (better)
tacc -d -> list available templates
tacc -M default -o template.cpp -> output the default template to template.cpp
Experimental and Undocumented Usage
-options:
-Ux print transitions before they are LALR merged with -l
-Us print states before they are LALR merged with -l
-Ui print input tokens before they are LALR merged with -l
-Cx enables printing of transitions within the compiler
-Cp enables printing of the parse tree within the compiler
-Ct enables lex (token) debugging within the compiler, up to 13 t's
-CM enables all lex (token) debugging within the compiler
-O switches back to the old BNF parser. Used for testing the new
BNF parser is identical. No real reason to use -O unless you
have found some spectacular bug with the new BNF parser.
-X enables regex-like extensions to token names. Needs -O.
Tokens ending in a regex like character * + ? - adds another
two productions as follows:
LHS ::= RHS* ... adds RHS* ::= RHS* RHS | NULL
LHS ::= RHS+ ... adds RHS+ ::= RHS+ RHS | RHS
LHS ::= RHS- ... adds RHS- ::= RHS RHS- | RHS
LHS ::= RHS? ... adds RHS? ::= RHS | NULL
And while this sounds like a nifty idea, it actually can create
conflicts fairly easily because of the extra intermediate non-terminal
in the heirachy. :(
-R switches to regex test mode, for more info on -R, use -R?
-L switches to lex test mode, for more info on -L, use -L?
-O use old BNF parser
-O uses the old bnf bootstrap parser that was hand written before tacc was operational enough to generate its own BNF parser. It is not as flexible as the new tacc generated one and shouldn't be used.
-OX enable experimental options
-X is best avoided regardless of what it says in the help above.
-R regex test mode
-R actually has some use. You can test what matches what with regular expressions.
> tacc -R?
usage: tacc -R "regex" ...
[-m match_string]
[-GWTV-?]
tacc -R tests the regex deterministic finite state (DFA) constructor
that is used in to build the regex lexical scanner.
-options:
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-RR help on regexes and regex classes.
-V Version
-- Stop -option parsing
-? This help message
Example:
tacc -R "int" "while" "[0-9]+" "[A-Za-z_][A-Za-z_0-9]*" -m "integrity"
Just looking at the example given in the help. There are 4 regexs there and the input is "integrity". He is hoping that integrity will be matched by regex #4 "[A-Za-z_][A-Za-z_0-9]*" and not by regex #1 "int". Even though the first part of "integrity" is "int", "integrity" is longer and the regex matcher matches the leftmost longest string.
Running the example shows tacc compiling the regexes to multiple non-deterministic finite state automatons (NDFAs) and then merging them into a single deterministic finite state automaton (DFA). It is similar to what tacc does when building a parser, but the regex automaton doesn't use any stack. Just being in a particular state is enough to recognise regular expressions.
> tacc -R "int" "while" "[0-9]+" "[A-Za-z_][A-Za-z_0-9]*" -m "integrity"
regex_test_main: regex 1 is int
NDFA:
Start 5
state 5 on epsilon --> 1
state 1 on i --> 2
state 2 on n --> 3
state 3 on t --> 4 MATCH 1
regex_test_main: regex 2 is while
NDFA:
Start 12
state 12 on epsilon --> 6
state 6 on w --> 7
state 7 on h --> 8
state 8 on i --> 9
state 9 on l --> 10
state 10 on e --> 11 MATCH 2
regex_test_main: regex 3 is [0-9]+
NDFA:
Start 16
state 16 on epsilon --> 13
state 13 on 0123456789 --> 14
state 14 on epsilon --> 13
state 14 on epsilon --> 15 MATCH 3
regex_test_main: regex 4 is [A-Za-z_][A-Za-z_0-9]*
NDFA:
Start 26
state 26 on epsilon --> 17
state 17 on ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 24
state 24 on epsilon --> 20
state 24 on epsilon --> 25 MATCH 4
state 20 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 24
regex_test_main: DFA compile:
DFA:
Start 1
State 1 on 0123456789 --> 2 MATCH 3
State 1 on ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghjklmnopqrstuvxyz --> 3 MATCH 4
State 1 on i --> 4 MATCH 4
State 1 on w --> 5 MATCH 4
State 2 on 0123456789 --> 2 MATCH 3
State 3 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
State 4 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmopqrstuvwxyz --> 3 MATCH 4
State 4 on n --> 6 MATCH 4
State 6 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrsuvwxyz --> 3 MATCH 4
State 6 on t --> 7 MATCH 1
State 7 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
State 5 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefgijklmnopqrstuvwxyz --> 3 MATCH 4
State 5 on h --> 8 MATCH 4
State 8 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghjklmnopqrstuvwxyz --> 3 MATCH 4
State 8 on i --> 9 MATCH 4
State 9 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijkmnopqrstuvwxyz --> 3 MATCH 4
State 9 on l --> 10 MATCH 4
State 10 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdfghijklmnopqrstuvwxyz --> 3 MATCH 4
State 10 on e --> 11 MATCH 2
State 11 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
regex_test_main: DFA compress:
DFA:
Start 1
State 1 on 0123456789 --> 2 MATCH 3
State 1 on ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghjklmnopqrstuvxyz --> 3 MATCH 4
State 1 on i --> 4 MATCH 4
State 1 on w --> 7 MATCH 4
State 2 on 0123456789 --> 2 MATCH 3
State 3 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
State 4 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmopqrstuvwxyz --> 3 MATCH 4
State 4 on n --> 5 MATCH 4
State 5 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrsuvwxyz --> 3 MATCH 4
State 5 on t --> 6 MATCH 1
State 6 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
State 7 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefgijklmnopqrstuvwxyz --> 3 MATCH 4
State 7 on h --> 8 MATCH 4
State 8 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghjklmnopqrstuvwxyz --> 3 MATCH 4
State 8 on i --> 9 MATCH 4
State 9 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijkmnopqrstuvwxyz --> 3 MATCH 4
State 9 on l --> 10 MATCH 4
State 10 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdfghijklmnopqrstuvwxyz --> 3 MATCH 4
State 10 on e --> 11 MATCH 2
State 11 on 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz --> 3 MATCH 4
match: s:001 m:000 c = '\x00'
match: s:004 m:004 c = 'i'
match: s:005 m:004 c = 'n'
match: s:006 m:001 c = 't'
match: s:003 m:004 c = 'e'
match: s:003 m:004 c = 'g'
match: s:003 m:004 c = 'r'
match: s:003 m:004 c = 'i'
match: s:003 m:004 c = 't'
match: s:003 m:004 c = 'y'
rex.match("integrity") = regex 4: [A-Za-z_][A-Za-z_0-9]*
As a state diagram it looks like this. You can follow the matching process above (lines that start match: ). You can see it started in state1, i, state 4, n, state 5 etc and eventually gets stuck in a loop on state 3 matching the 4th regex which is a variable id. Double outline circles are accept states.
 |
-L lex test mode
-L actually has some use. You can test what the lexical scanner does.
> tacc -L?
usage: tacc -L [-ctTwslnN] {"plain_string_token" | "/regular_expression_token/"} ...
{[-e] [-E escape_character] -i match_string | -f input_filename.ext}
[-x expected_output]
[-GWTV-?]
tacc -L tests the regex lexical scanner.
-options:
-c ensure token ids for single character token names = ascii of the character
-t print tokens as they are read (more t's for lexical scanner debug info)
-k don't use context aware lexing
-K lexical scanner debug everything, equivalent to -ttttt...
-w don't ignore end of lines (\n, \f) (\r is always ignored)
-ww don't ignore any whitespace (\n \f \v \t ' ') (\r is always ignored)
-s short output format (for regression tests, same format at -x expects)
-l dump regex lex tables
-n do not execute the parser (used to show the debug tables when parsing might go nuts)
-e -i input_string contains escape sequences (like \n) that need to be descaped
-E escape_character, like -e above, but escape sequences start with escape_character
-N suppress warning messages
-G debug
-W wait for enter key before exiting
-T print time taken
-D once enables descape of words in [ ]. Use -DD for more help.
[NAME], [xHX], [oOCT], [aDEC], [NNN]
-RR help on regexes and regex classes.
-V Version
-- Stop -option parsing
-? This help message
Examples:
tacc -L "int" "while" "=" "/[0-9]+/" "/[a-z]+/" "/[[:space:]]+/" -iw "int interest = 40"
tacc -L "int" "while" "=" "/[0-9]+/" "/[a-z]+/" -i "int interest = 40"
tacc -Ls "/[a-z]+/" "=" "/[0-9]+/" -i "that = 86" -x "1:that, 2:=, 3:86, EOS"
Here is tacc doing the second example in the help:
> tacc -L "int" "while" "=" "/[0-9]+/" "/[a-z]+/" -i "int interest = 40"
lex_test_main: assign token 1 = "int"
lex_test_main: assign token 2 = "while"
lex_test_main: assign token 3 = "="
lex_test_main: assign token 4 = "/[0-9]+/"
lex_test_main: assign token 5 = "/[a-z]+/"
Tokens
1. real not_null terminal input plain int
2. real not_null terminal input plain while
3. real not_null terminal input plain =
4. real not_null terminal input regex /[0-9]+/
5. real not_null terminal input regex /[a-z]+/
6. virtual not_null terminal - plain UNKNOWN
7. virtual not_null terminal - plain ERROR
8. virtual not_null terminal - plain EOS
9. virtual not_null terminal - plain ANY
10. virtual nullable terminal - plain NULL
11. virtual not_null terminal - plain START
lex_test_main: lexing string: int interest = 40
{1 int = "int"}
{5 /[a-z]+/ = "interest"}
{3 = = "="}
{4 /[0-9]+/ = "40"}
{8 EOS = ""}
-L -s lex test mode, short output
-Ls prints out a short one line lex of the input. This is mainly for regression testing:
> tacc -L "int" "while" "=" "/[0-9]+/" "/[a-z]+/" -i "int interest = 40" -s
1:int, 5:interest, 3:=, 4:40, EOS
-L -others debug
Other options will have you drowning in debug, go for it.
How to LR(1) parse (by hand)
LR 101
First you generate the list of predicate follow states based on the possibili... oh noes not that explanation again! Can't you make it simpler than that?!
grammar.bnf
Let's go slow, starting with a very simple grammar, with 2 productions: Productions have the form LHS ::= RHS. We say Left Hand Side (LHS) becomes (::=) Right Hand Side (RHS). The LHS is always one token, the RHS can be many tokens.
This grammar accepts the input x y z. An x followed by y, followed by z. Once. Just x y z.
GOAL ::= expr
expr ::= x y z
State Pushdown Automaton
We are building a state pushdown automaton from a bnf grammar. Sounds fancy.
State 1
Start with state 1.
State 1
Find the GOAL
Find the token that is the GOAL token. In tacc, the GOAL token is the first token in the bnf file. Which is the LHS of the first production. Here the GOAL token is GOAL.
Write the Goal production out:
State 1
GOAL ::= expr
Add the parse cursor .
Put a dot . after the ::=, before the RHS of the production. This is the parse cursor:
State 1
GOAL ::= . expr
Add the follow set
The goal production will always be followed by the end of string EOS. Put that after the production. This is called the follow set:
State 1
GOAL ::= . expr EOS
Expand non-terminals
For every token to the right of the parse cursor dot . (in this case expr) find a production with a matching left hand side and add it to the state. Don't worry if there aren't any:
State 1
GOAL ::= . expr EOS
expr ::= x y z
It too will have a parse cursor dot . placed just after the ::=
State 1
GOAL ::= . expr EOS
expr ::= . x y z
And it will inherit the follow set of the production it was expanded from:
State 1
GOAL ::= . expr EOS
expr ::= . x y z EOS
Make (shift) transitions (and close the state)
Now x has a dot in front of it, so we look for a production with an x as the LHS. And there aren't any. So we say that x is a terminal token. Terminal tokens do not expand and really do occur in our input stream. expr and GOAL appear on the LHS of the productions. We call them non-terminal tokens because they expand to other tokens. Non-terminal tokens do not occur in our input stream.
Now for each production in state 1, we create another state. Taking the first production in state 1:
GOAL ::= . expr EOS
We see that the right of the parse cursor . has a token. We say, "In state 1, on an expr, go to state 2" Where 2 is the new state:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z EOS
And we make state 2:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z EOS
State 2
Then we add all of the productions in state 1 that have . expr in them to the newly created state 2, but shift the parse cursor . one token to the right. We also take the follow set, but not the go to state number. In this case only one production needs to be taken:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z EOS
State 2
GOAL ::= expr . EOS
Now we go back to state 1 and continue with the second production:
expr ::= . x y z EOS
We see that the right of the parse cursor . has a token. We say, "In state 1, on an x, go to state 3" Where 3 is a new state:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . EOS
And we make state 3:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . EOS
State 3
Then we add all of the productions that have . x in them to the newly created state 3, but shift the parse cursor . one token to the right. We also take the follow set, but not the go to state number. In this case only one production needs to be taken:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . EOS
State 3
expr ::= x . y z EOS
And state 1 is now closed.
State 2 - make reductions
Now we do the same for all the new states, starting with state 2.
State 2 only has one production:
GOAL ::= expr . EOS
But this time the parse cursor . is at the end of the production. We say, "In state 2, on an EOS, reduce GOAL ::= expr" The reduce is a curly arrow and tacc writes it like _o->
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z EOS
And state 2 is now closed.
State 3
Moving on to state 3.
State 3 only has one production:
expr ::= x . y z EOS
We see that the right of the parse cursor . has a token. We say, "In state 3, on a y, go to state 4" Where 4 is a new state:
And we make state 4:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z ---> 4 EOS
State 4
Then we add all of the productions that have . y in them to the newly created state 4, but shift the parse cursor . one token to the right. We also take the follow set, but not the go to state number. In this case only one production needs to be taken:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z ---> 4 EOS
State 4
expr ::= x y . z EOS
And state 3 is now closed.
State 4
Moving on to state 4.
State 4 only has one production:
expr ::= x y . z EOS
We see that the right of the parse cursor . has a token. We say, "In state 4, on a z, go to state 5" Where 5 is a new state:
And we make state 5:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z ---> 4 EOS
State 4
expr ::= x y . z ---> 5 EOS
State 5
Then we add all of the productions that have . z in them to the newly created state 5, but shift the parse cursor . one token to the right. We also take the follow set, but not the go to state number. In this case only one production needs to be taken:
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z ---> 4 EOS
State 4
expr ::= x y . z ---> 5 EOS
State 5
expr ::= x y z . EOS
And state 4 is closed.
State 5
Moving on to state 5.
State 5 only has one production:
expr ::= x y z . EOS
This time the parse cursor . is at the end of the production. We say, "In state 5, on an EOS, reduce expr ::= x y z" The reduce is a curly arrow and tacc writes it like _o->
State 1
GOAL ::= . expr ---> 2 EOS
expr ::= . x y z ---> 3 EOS
State 2
GOAL ::= expr . _o-> EOS
State 3
expr ::= x . y z ---> 4 EOS
State 4
expr ::= x y . z ---> 5 EOS
State 5
expr ::= x y z . _o-> EOS
And state 5 is closed.
And we are done. The state automaton has 5 states.
Of course this is a simple example and doesn't show all the nuances of state creation, but it is the core of how it is done. We will walk through a more complicated example later on.
Pushdown Automaton
Once the automaton is built, we can discard some of the information in the states. We only need to know 1. the state we are in, 2. the token we have and 3. the transition action - either the state to go to or the reduction to do.
When a transition action is a go to another state, it is called a shift transition.
When a transition action is a reduce, it is called a reduction transition.
We can extract the vital information from the state pushdown automaton to give us a pushdown automaton:
State 1 on expr ---> 2
State 1 on x ---> 3
State 2 on EOS _o-> GOAL ::= expr
State 3 on y ---> 4
State 4 on z ---> 5
State 5 on EOS _o-> expr ::= x y z
Graphically it looks like this:
 |
Parsing input x y z
If you were following the diagram and trying to parse the input x y z.
Start in state 1, add the parse cursor . before the input, then the input x y z, then the end of string token EOS:
state 1: . x y z EOS
So in state 1, on an x, go to state 3
state 3: x . y z EOS
In state 3, on y, go to state 4
state 4: x y . z EOS
In state 4, on z, go to state 5
state 5: x y z . EOS
In state 5, on EOS, reduce expr ::= x y z. OK... But what state are we in now? This is where the pushdown in pushdown automaton comes in.
As we shift through the states during the parse, we push the state number on to the state stack as we go. When we reduce, we pop off the number of states off the state stack equal to the number of tokens on the RHS of the reduction (not the whole story yet, but stick with it for now. We need to adjust for NULLs as well.)
If we were keeping a state stack, it would be 1, 3, 4, 5. The numbers of all the states we have visited so far.
There are 3 tokens in this reduction, x y z, so we pop 3
states off the stack: 1, 3, 4, 5
and end up back in state 1.
The reduction also replaces everything on the RHS of the reduction (x y z), with what is on the LHS (expr).
The parse cursor . is placed before the LHS.
And it now looks like this:
state 1: . expr EOS
In state 1, on expr, go to state 2
state 2: expr . EOS
In state 2, on EOS, reduce GOAL ::= expr.
The state stack is 1, 2. There is 1 token on the RHS of the
reduction, so pop off 1 state from the state stack: 1, 2 and end up in state 1 again.
The reduction also replaces everything on the RHS of the reduction (expr), with what is on the LHS (GOAL).
The parse cursor . is placed before the LHS.
And it now looks like this:
state 1: . GOAL EOS
In state 1, on GOAL with no more input, is the condition to accept the string. (Some would say we need to shift the GOAL and maybe even the EOS, but tacc doesn't bother and saves a few cycles)
We are done.
Doing exactly the same thing with tacc
States
We could have done the states with tacc -s:
> tacc xyz.bnf -s
tacc: reading grammar file: xyz.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
States
---- START ---> state 1
| 1. GOAL ::= . expr ---> 2 EOS
| 2. expr ::= . x y z ---> 3 EOS
--------------------
---- expr ---> state 2
| 1. GOAL ::= expr . _o-> -1 EOS
--------------------
---- x ---> state 3
| 2. expr ::= x . y z ---> 4 EOS
--------------------
---- y ---> state 4
| 2. expr ::= x y . z ---> 5 EOS
--------------------
---- z ---> state 5
| 2. expr ::= x y z . _o-> -2 EOS
--------------------
Parser States: 5
Lexical States: 2
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(0)
You can see that tacc has created a number for each production. Also the transition action is a positive number equal to the state number for a shift action and a negative number corresponding to the -production number for each reduction action.
Transitions
And the transitions with tacc -x:
C:\Trev\Projects\tacc\Debug>tacc xyz.bnf -x
tacc: reading grammar file: xyz.bnf
tacc: checking productions
tacc: building automation
tacc: building lexer
Transitions
state 1 on expr ---> 2
state 1 on x ---> 3
state 2 on EOS _o-> GOAL ::= expr
state 3 on y ---> 4
state 4 on z ---> 5
state 5 on EOS _o-> expr ::= x y z
Parser States: 5
Lexical States: 2
Shift-Reduce conflicts: 0
Reduce-Reduce conflicts: 0
Warnings: 0
Errors: 0
Automaton is LR(0)
Parsing input
And after compiling with tacc xyz.bnf -o xyz.cpp, we could parse the input x y z with tacc -I:
> tacc -I xyz.cpp "x y z" -x
state 1 on 8 x ---> state 3
state 3 on 9 y ---> state 4
state 4 on 10 z ---> state 5
state 5 on 2 EOS _o-> state 1 reduce 2: expr ::= x y z
state 1 on 7 expr ---> state 2
state 2 on 2 EOS _o-> state 1 reduce 1: GOAL ::= expr
xyz: string accepted